You can rule out electric forces by just grounding the masses to have them at equal potential, at least as long as your test masses are conductive. Magnetic forces seems harder, use a non-magnetic material does not really help, how would you know that it is not ever so slightly magnetic, maybe even just due to contamination? Maybe try different materials and find that the effect scales with mass but seems independent of the material, that could increase confidence as it seems unlikely that different test masses made of different materials would exhibit the same tiny magnetic forces. Also I would first do a calculation, I have no idea how the gravitational forces compares to say paramagnetic effects you might encounter, for all I know they could be of similar size or orders of magnitude apart.
How about deliberately putting a strong magnet close to the rotating test masses, then repeating the experiment with the magnet on the other side and verifying that it doesn't make a difference?
Of course, that might be the easiest way. Given that you can get tiny magnets that are pretty strong but only a millimeters or so in size and therefore also light, you could just stick them to your different test masses in various configurations and see if it makes any difference while leaving the mass distribution pretty much unchanged.
The metal masses over a styrofoam bar look as a serius problem because they may collect static electricity. Perhaps a thin coorer wire that connect them to the aluminium foil in the water may solve that.
Did the author factor in the impact of this kind of article on the external perception of the rationalist / utilitarian / EA community when weighing the utility of publishing this?
Should you push arguments that seem ridiculously unacceptable to the vast majority of people, thereby reducing the weight of more acceptable arguments you could possibly make?
I think this is a tough call in general. Current morality would be considered "ridiculously unacceptable" by 1800s standards, but I see it as a good thing that we've moved away from 1800s morality. I'm glad people were willing to challenge the 1800s status quo. At the same time, my sense is that the environmentalists who are ruining art in museums are probably challenging the status quo in a way that's unproductive.
To some degree, I suspect the rationalist / EA crowd has decided that weird contrarians tend to be the people who have the greatest impact in the long run, so it's OK to filter for those people.
How palatable an argument is determines its actual impact. It's not logical to spend effort making arguments that are so unpalatable that they will just make people ignore you.
The author leads infrastructure at Cresta. Cresta is a customer service automation company. His first point is about how happy he is to have picked AWS and their human-based customer service, versus Google's robot-based customer service.
I'm not saying there's anything wrong, and I'm oversimplifying a bit, but I still find this amusing.
Haha very good catch. I prefer GCP but I will admit any day of the week that their support is bad. Makes sense that they would value good support highly.
We used to use AWS and GCP at my previous company. GCP support was fine, and I never saw anything from AWS support that GCP didn't also do. I've heard horror stories about both, including some security support horror stories from AWS that are quite troubling.
> this is only for paid surface parking for non-residents. Residents price is not impacted (which is controversial). Underground parking is private and not affected. Free parking (outside of 8AM to 8PM Monday to Saturday) stays free for everyone.
If my end goal was to apply this to everyone at some point, I would probably start with such a restricted law, then extend it step by step later.
The news makes people focus on this particular vote, but it's just yet another small step in the multitude of other steps to curb car use in Paris.
It started at least 10 years ago (current mayor that really pushes the issue was elected in 2014, I'm not sure it's the actual starting point), and we saw:
* bike lanes. Lots of bike lanes. Generally replacing traffic lanes and parking spots.
* several pedestrians zones replacing traffic lanes (especially in front of schools).
* Crit'air restrictions (car pollution rating, derived from Euro rating). You cannot drive a polluting car in Paris anymore.
* reduction of the speed limit from 50km/h to 30km/h in Paris, and from 80km/h to 70km/h on the Périphérique (highway circling Paris)
* there is no longer any always-free surface parking spot, and price has been raised a lot
Yes, regarding the metaverse it is. But I think even if they weren’t trying to get into VR they’d be doing the same thing. The existence of other tech companies with massive margins and employee headcount impacts Meta’s bottom line, because it has to compete against them for hiring.
One of the things I like about Meta is they didn’t play into the wage collusion of Google, Apple and friends. Their expansion drove increased pay across the board in tech - but because Google was also in the advertising business they had similar constraints on max revenue per employee.
If AI supports even higher revenue per employee than advertising, which is entirely possible, it would undermine their strategy of having the best pay among big tech companies to attract top talent, because someone would have deeper pockets.
So in the article about 200 miles driving (in California) is 1 in a million chance of dying. So lets use that number nationwide to be lazy.
Now we can move a decimal point over. So the death chances of a Chicago to LA drive is 100,000 in one. But you drive back, so then its that twice. Once in 50,000 people dying on a Chicago to LA and back roadtrip is extremely frightening. How many people from the midwest make this drive a year? Or from the east coast? How many don't make it back?
The USA, on average, has 100+ fatalities via auto transportation a day.
The above ignores serious injury, permanent disability, etc. Its just death. The chances of having to deal with a broken spine, losing a limb, blindness, 3rd degree burns all over your body, etc aren't even calculated, but those are real and far more common than death. Death being harder to achieve with modern medical treatments.
Cars are extremely dangerous. We downplay what it means to drive.
I wondered about that reading some of the comments about the 737 Max. We routinely travel in exponentially more risky ways all the time, yet we expend time thinking about the safety benefit of avoiding a specific type of aircraft.
Not downplaying airline safety as a whole there, but thinking about it for yourself on a personal level is maybe not moving the needle.
Agreed. It must’ve been terrible for the people on that plane, but I don’t think it’s worth my time to worry about what plane I’m flying on, or what the maintenance record of the airline is. For developed countries, they’re super good enough.
As a cyclist that’s trying to not die, I also have to assume this heavily depends on where you’re cycling. Along a stroad? You’re dead. Country road with more bikes than cars? Much safer.
Also you can rack up miles on the interstate like no one's business on a road trip etc. imo it should be by unit time not unit distance but I could see the argument for distance
Same with planes. Like yeah if you wanted to make the same trip without a plane it's way more dangerous but what if you just wouldn't take the train from coast to coast in the first place?
IDK, imo time is the most important tradeoff for transport when doing per capital/etc measurements
Some context for people unfamiliar with ML research:
the author, Schmidhuber, is well known for claiming that he should get credit for many ML ideas. Most ML researchers think that:
- He doesn't deserve the credit he claims, in most if not all cases.
- There's a few cases where his papers should have been cited and weren't. That's fairly common.
- People do not get much credit for formulating an abstract idea in a paper or implementing it on a toy problem. Credit belongs to whoever actually makes it work.
- Credit assignment in ML is not perfect but roughly works.
>> Credit belongs to whoever actually makes it work.
That is according to whom? Is it a rule you just came up with or accepted practice? And if it's accepted practice, in what community is it accepted practice? Because where I publish and review there's really no such rule and credit belongs to the people who deserve credit for the work they've done that was useful to others.
> credit belongs to the people who deserve credit for the work they've done that was useful to others
Certainly agree. The point is that coming up with the idea, writing it as an equation, or an architecture diagram in a paper, is a small fraction of the effort that goes into making the idea work in a model showing good performance on real life datasets.
For example, just taking a random paper that Schmidhuber claims should give him credit for GANs, https://people.idsia.ch/~juergen/FKI-126-90ocr.pdf hopefully you can easily see that a lot of work would be needed to turn this into a realistic image generation model. And that is, even if you admit that the idea is strongly related to GANs, which I'm not convinced of but won't spend time on.
> Credit belongs to whoever actually makes it work.
>> That is according to whom? Is it a rule you just came up with or accepted practice? And if it's accepted practice, in what community is it accepted practice?
It is accepted practice in the ML community. If it weren't, Schmidhuber wouldn't be complaining.
I agree a significant amount of work (and often insight too) is needed to translate an architecture idea into something that works in practice, and there are certainly plenty of ideas that are obvious in the abstract. But I also think it's important to avoid dismissing work only on the basis that it doesn't involve "real life datasets".
Deep learning is a relatively unexplored field and there are many open mathematical and scientific questions to ask that involve only model equations or contrived datasets. Novel theoretical results are not just about some architecture idea but about proving facts that can be useful for understanding how the model class would perform in different scenarios. Which in turn can help shape the search space for applied work.
Additionally, I don't think credit assignment should be so discrete. 100% agree that vomiting out vague ideas shouldn't grant claims to credit, but academic science much too often gives only a single author the "real" credit.
Incidentally, in other fields the person who actually makes it work very well may not be the person that receives this credit. Like biology can involve a lot of hard manual work (that isn't really intellectual) in order to realize a project plan. It varies how much of the credit those people receive, and I'm not even sure how much they should receive. This topic is extremely nuanced.
"Introductory theoretical work in GAN was done by Schmidhuber [1], but it was not until large experimental efforts [2,3,4] on image generations that the power of GANs was revealed."
I don't buy that this is standard practice in the ML community, and even if it is it's BS. If the basic idea/principle has been published previously but in a different context you should cite it and say why the solution is not directly applicable or has not been evaluated in the current context. Anything else is unprofessional.
Agreed. The piece anticipated this straw man argument:
> "the inventor of an important method should get credit for inventing it. She may not always be the one who popularizes it. Then the popularizer should get credit for popularizing it (but not for inventing it)." Nothing more or less than the standard elementary principles of scientific credit assignment.[T22] LBH, however, apparently aren't satisfied with credit for popularising the inventions of others; they also want the inventor's credit.[LEC]
Basically ideas are a dime a dozen. Sure, your idea might be a good one, but how do we spot your grain of sand is special when it looks the same as the rest of the desert? Essentially having an idea isn't useful to others. Demonstrating that your idea has legs is useful to others.
I don't have to deal with citing papers, but I once had to deal with people pitching me ideas, wanting me to sign an NDA, in exchange for 50% of the revenue after I did all the actual work. Just out of curiosity, I signed one once. It was a fart app, IIRC. They thought a fart app needed an NDA, and that I'd then go do all the work and give them 50% because they "had the idea". It was so laughably sad.
If you think these ideas are valuable, I have a beautiful clock for you. It is right twice a day. You'll have the same problem: you won't know when it's right. You'll need someone else's work to tell that.
There's a spectrum of ideas, from groundbreaking to "dime a dozen". In tech startups, and in almost all of computer science, most ideas are a dime a dozen, and the value is in the execution.
But clearly, some ideas are groundbreaking. Einstein rightfully gets the credit for an on-paper hypothesis that wasn't proved until decades later via a chain of critical discoveries and experimental innovations by other people. It's legit to call it Einstin's relativity, and not Mossbauer/Hay's relativity.
Ideas are a dime a dozen in the sense that the same idea will often occur to dozens of people, on a dime's worth of effort. Relativity theory wasn't anything like that. Einstein made predictions that no one else was making. When one of them from GR was confirmed a few years ago, Lenny Susskind famously marveled at the foresight, saying "they didn't call him Einstein for nothing!".
Problem then goes to how do I decide whether this particular idea is a dime a dozen or a unique idea... Everyone ends up going by feels when answering this question for any particular problem.
This is nothing to do with ideas. Schmidhuber is complaining that his published work was plagiarised. In machine learning research, in order to publish your work you have to show that your proposed approach works and to do that you have to beat some benchmarks and establish a new state of the art, otherwise there's no publication. That takes work and that's the work that Schmidhuber claims was inappropriately left uncited. In fact that's exactly the kind of work that Hinton, LeCun and Bengio have always done. That's what machine learning researchers do.
This ... idea that Schmidhuber is an ideas man who's never done any real work is Hinton's allegation, and it's clearly designed to misrepresent both Schmidhuber and his work in order to discredit his complaints. And I'm sorry to say that people on HN have fallen for it hook, line and sinker, I guess because that's what social media says.
Btw, the point I make, that you don't get published in machine learning without beating some benchmarks and establishing a new state of the art, I can attribute that to none other than Hinton himself, in an interview with Wired, whence I quote, by the by:
>> What we should be going for, particularly in the basic science conferences, is radically new ideas. Because we know a radically new idea in the long run is going to be much more influential than a tiny improvement.
So that's the guy accusing the other guy of being nothing but an ideas man and that you don't need to cite someone who first came up with an idea, saying that "new ideas" are important.
But that's just Hinton presenting things just the way he likes. Now ideas are important, now they're not, as he pleases.
I don't know enough about this area of research to have an opinion on this particular topic, but I've noticed a trend with this sort of thing with my colleagues. They both claim at different times, depending on whether it benefits them, that
(1) Ideas are a dime a dozen, and making it work or bringing it to fruition, is the important thing
and
(2) The idea is the important thing; the specific implementation by someone doesn't matter, as they're just doing what the idea creator or discoverer laid out for others to follow.
Sometimes I feel like there's a fundamental paradox there that arises a lot in numerous areas of work, business, and economics.
>Most ML researchers think that: He doesn't deserve the credit he claims, in most if not all cases.
That deserves a source. Especially for "all cases"; I don't think anyone who understands machine learning could read some of his earlier papers and still think Ian Goodfellow invented GANs.
Frankly, I do, and it comes across as quibbling about categories and trying to define unnecessarily general taxonomic categories, as a reaction to positive reactions to other people.
ex. in the article:
"Goodfellow eventually admitted that my PM is adversarial...but emphasized that it's not generative. However, [it] is both adversarial and generative (its generator contains probabilistic units)...It is actually a generalized version of GANs."
When you're at "actually, probabilities means generative, and actually you know what, even my initial claim was too specific: turns out its a generalized version of GANs", all in service of arguing a paper should have been cited in another paper, years after the other paper has been published, there's not much room for sympathy.
Agreed, Ian Goodfellow wasn't the first to come up with the idea of jointly training a generator and discriminator. But he was the first to make it work for image generation with modern neural networks. For that Ian Goodfellow deserved to get most of the credit, and he did.
While I generally agree with you in these specific cases, I feel like this is a shortsighted form of argument nonetheless. Coming up with an idea begets a scalable implementation of it and it's not very wise to ascribe absolute value solely on one side of the equation.
I think it's less about scalability and more about identifying specific choices that are promising. A lot of Schmidthuber's work paints out broad ideas in grand strokes and suggests hundreds of potential neural networks without evaluating what choices in that massive space are good. He then claims credit when other people identify the specific one or two of those hundred models (often with minor variations that make it not immediately obvious whether it perfectly fits the broad definition or not) that are actually promising.
But if other people identify and further develop one or two out of his models, he should still be cited. If they did not use his work at all, coming ith one or two models independently, then that's a different situation. It's a bit of an honor code thing as well, it's hard to prove if somebody has a read a paper or not. But then there's a more stringent standard where one cites as part of surveying preexisting work, which can result in a vast list.
Let's take an example: his "unnormalised linear Transformer," a neural network with "self-attention" published in 1992 under another name. It wasn't just an idea, it was implemented and tested in experiments. However, few people cared, because the computational hardware was so slow, and such networks were not yet practical. Decades later, the basic concepts were "reinvented" and renamed, and today they are really useful on much faster computers. Unquestionably, however, their origins must be cited by those who are applying them.
Why are some people here even debating the generally recognised rules of scientific publishing mentioned in the paper:
> The deontology of science requires: If one "reinvents" something that was already known, and only becomes aware of it later, one must at least clarify it later, and correctly give credit in all follow-up papers and presentations.
The sad part is that Schmidhuber is not a grifter by any means. If the turning prize for deep learning could go to 5 people instead of 3, he would very likely be on that list.
His lab is excellent and was easily Europe's best deep learning lab for decades before it blew up.
Some of his complaints are valid too. European labs often get ignored, and he has been sidelined despite being one of the most important people in deep learning himself.
But man doesn't know when an argument runs out of gas. His claims get grander with every passing year.
He would've just been the 'get off my lawn' grandpa of deep learning, but he somehow comes across as even more insufferable than that.
I wonder if 2023 schmidhuber was created because the polite one from a decade ago was ignored. A sort of evil phase, if you will.
I feel bad for him. He did get passed over of some deserved awards and recognition. But he reeks of resentment and thats never a good look.
> I feel bad for him. He did get passed over of some deserved awards and recognition. But he reeks of resentment and thats never a good look.
It's a terrible look. We're in the middle of one of the biggest gold rushes in tech history and he's wasting time complaining when he claims to be one of its pioneers? That effort is much better invested in building stuff but I suspect he's fallen into the classic PI trap of writing grants all the time and leaving the real work to the rest of the faculty, atrophying his skills too much to do anything now that the industry is moving so quikcly.
His students you mean, otherwise he would be first author. Academia is just like capitalism, with credits substituting for capital. The capital owner (laboratory head/professor) always gets a cut of everything published.
Authorship conventions vary a lot within the academia. In general, the closer the name is to either end of the author list, the more significant their contributions likely were.
Things also vary from paper to paper. Sometimes the first author just did the actual work for somebody else, and sometimes they also made significant intellectual contributions. (If the first author is listed as the sole corresponding author, it usually indicates the latter.) Sometimes the last/senior author just brought the money in, sometimes they were primarily mentoring the first author, and sometimes they were the driving force behind the project.
In some fields and some situations, last-author papers are actually more valuable than first-author papers. A first-author paper tells that you are capable of working as a junior researcher, while a last-author paper is a signal of your success as a senior researcher.
I once had a paper where I shared first authorship with four other people. That implies that the project was large enough that different people were in charge of different subprojects. Which in turn implies that the senior author must have made major contributions by being in charge of the entire project.
This is getting off-topic, but I've given up making heads or tails of authorship.
I know senior authors who are last on a paper just because they're senior and realize they (1) didn't really contribute much at all (they might have just inserted themselves on a paper), and (2) invoke the old meaning of last author knowing that the meaning has changed, so they end up being "the senior author" who gets a lot of credit just because they're senior.
Even producing the data takes on new meaning in an age of open science where datasets are distributed freely. What's the difference between citing an original study paper to give credit to the study PIs, and having them as a last author? Should someone who generates a dataset be last author on every paper using that data?
> In general, the closer the name is to either end of the author list, the more significant their contributions likely were.
In ML, NLP, and many Humanities too, the supervisor (supervising professor/postdoc, lab head, PI) is put last regardless of contribution. The rest of the author list is ranked in descending order for contribution. Often the last author's contributions are very limited to obtaining funding or proof-reading.
Now this practice is controversial with many venues stating that obtaining funding and only supervising is not a valid reason for authorship, but in my experience this practice doesn't die out.
Agreed, although I personally prefer when actual experts are communicating to the public. But that's not all he's doing, Tegmark also intends to influence global policy on AI research, random example: https://www.theguardian.com/technology/2023/sep/21/ai-focuse...
I independently arrived at[0] something close to Max Tegmark's idea of the Mathematical Universe, almost nobody noticed and fewer still cared because I published it as a LiveJournal blog post whereas he fleshed it out into a whole book.
I didn't get credit because I didn't do the hard work that deserves credit, I had the flash of inspiration and stopped after a few paragraphs of mediocre student philosophy.
The main problem with Alexa / Google Assistant / Siri is that the tech was not ready when they launched. We didn't have models that could understand non-trivial user requests, generate non-trivial actions or keep track of context properly. Now we do.
Amazon, Apple and Google are all working on incorporating LLMs but why is it taking so long? Why are these assistants still so bad? ChatGPT has been available for a year, GPT3 API for 3 years. I suspect some of it is legacy tech and legacy researchers from the pre-LLM era.
How often would ChatGPT hit the exact API you expect with the exact request you need in 1 shot. People I know will still very often try 5 prompts before they get what they wanted from LLMs, that doesn't work in a Siri world (or its just as frustrating)
With ChatGPT some of the limitations of the tech are handled by the user e.g. starting a new chat when you want to discuss a new topic. An assistant has to detect changes in user context somehow. Also, I think it would be harder to know what to inject in the prompt since conversations are more like context based RAG rather than topic (embedding) based.
Then you have all the usual generative issues: hallucinations, alignment, sticking within guardrails, no repeatable testing, drift. The potential for errors at that scale is pretty staggering.
No, the main problem is that these projects were grossly mismanaged and didn't really have a concrete purpose. It would've been possible to build something incredibly useful without LLMs, I just don't know why they didn't. Though the top comment I feel answers that question quite clearly. These assistants were never developed to be useful.
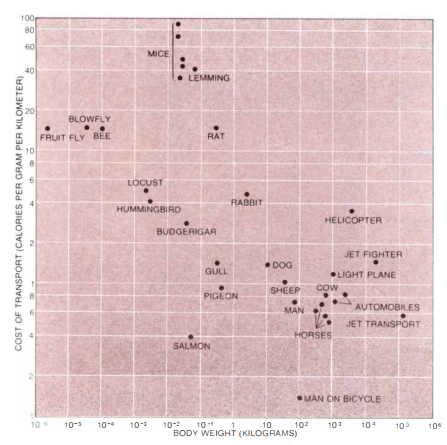
When is that measuring the salmon? Surely, calories per gram per kilometer is very high if you're swimming upstream and low when you're going downstream, right? Is this when they're in the ocean phase?
Would you have an issue if that someone subsequently refused to part with 0.001% of their thankyou notes in order to save someone else's life?
This is a terrible analogy because it captures the good reason why there are billionaires (we reward them for building something useful) and none of the problems that come with it (wealth and power inequality, economic externalities, etc.)
{kind=link}