Well, I happen to use it everyday. I honestly don't know what exactly is "terrible/horrible/awful" about it. I'm neutral about its UX - neither memorable nor despicable.
It may be missed if the new app's UX turns out to be worse on whatever metrics you're using.
My understanding is that the synthetic training data helps capture abstract time-series patterns that are common in all domains.
As they say in appendix 8:
> We create the synthetic data to reflect common time-series patterns using traditional statistical models. We start with four simple times series patterns:
> • Piece-wise linear trends (I), where the number of the piece-wise linear components is randomly chosen between 2 and 8.
> • ARMA(p, q) (II), where 1 ≤ p, q ≤ 8 and the corresponding coefficients are generated from either a multivariate Gaussian or a uniform, then normalized.
> • Seasonal patterns. In particular we create the sine (III) and the cosine (IV) waves of different random periods between 4 and max context length / 2 time-points and time delays.
If there were no such underlying patterns in the class of all time-series data, then even the idea of traditional time-series models would be fundamentally misplaced.
And since this is a transformer model, it also looks for patterns in the problem-specific input data at inference time, just like how the input context to an LLM influences its output's relevance.
I thought the title meant the training data used was ethics content and ethical reasoning. Turns out "ethically trained" means the training data used doesn't violate copyright laws.
Given the extent to which the copyright system has benefited corporations and publishing companies to the detriment of individual authors and the general public, I'm constantly surprised that it still has many apologists.
As we don't live in a world where the rich patronize the arts some sort of copyright system is the only way authors and artists are gonna make a living doing their thing. ...though I suppose proponents of Universal Basic Income (UBI) would disagree, but between the abolishment of copyright, the institution of UBI, or a 7 year old child being hit by 7 lightning strikes and 7 meteor impacts and surviving; the latter seems the most likely.
People imagine poor author having their thing stolen rather than poor author that corporate takes IP from by contract agreement (and if you don't do that, you don't get the job), then abuses for 70+ years
It would be interesting to talk with a victorian-era chatbot, including victorian-era ethics. would be interesting to see how much divergence from modern era ethics it would have.
I believe the works are no longer under copyright. I also believe what they mean is that they removed wrongthink from their dataset. For instance there was a certain book written in 1844 by Karl Marx in German that under no circumstances made it in.
This ofc means that the LLM is completely pointless.
If training data of any kind violated copyright, every creator alive would be in breach of by virtue of any influence their “training data” (lifelong exposure to the work of others) has on their output.
The creators crying foul of AI are painting themselves into a corner, both literally and figuratively.
This is a truly awful argument that keeps coming up. It relies on the false equivalence between training an AI (a technical process that involves copying a work into computer storage), and a human being experiencing a work, which doesn't involve any kind of copying (and usually involves the human legally purchasing the work, which AI companies did not do).
There is a legal difference as well as a technical difference. AIs don't learn the same way human brains do. The law does not treat these things the same. You may want to draw an analogy between the two and say they're "basically the same", but they are not basically the same. They aren't the same at all, outside of a very weak analogy. Is training kind of sort of like human learning? Yes. That doesn't mean anything. Dogs are kind of sort of like children, but if you try to treat your child the way you treat your dog, you end up in prison. Because children aren't dogs, either in reality, or in the eyes of the legal system.
Please, AI boosters, stop using this one. Human brains aren't clocks. Human brains aren't computers. Human brains aren't LLMs. AI training does not mimic human learning in any significant way.
> these tools until AI had the common property of being enhancing of human cognition, because they couldn't do the thinking for you
I have a different take, centered around this idea: Not everyone was into thinking about everything all the time even before AI. I'd say most people most of the time outsourced actual thinking to someone else.
1) Reading non-fiction books:
Not all books, even the non-fiction ones, necessarily require any thinking by the reader. A book that narrates history, for example, requires much less thinking than something like "The Road to Reality" or "Godel Escher Bach."
Most of us outsourced the thinking and historical method to the authors of the history book and just passively consumed some facts or factoids. Some of us memorize and remember these factoids well, but that's not thinking, just knowledge storage.
Philosophically, what's the difference between consuming books this way and reading an LLM's output?
2) Reading research papers:
Most people don't read any research papers at all. No thinking there.
Most people don't head to some forum to ask about latest research either.
Also, researchers in most fields don't come out and do outreach regularly.
Indeed, an LLM may actually be the only pathway for a lot of people to get at least _some_ knowledge and awareness about latest research.
Those of us in scientific, engineering, humanities, healthcare fields may read some to many papers.
But only a small subset reads very critically, looking for data errors, inconsistencies, etc.
For most of us, the knowledge and techniques may be beyond our current understanding and possibly without any interest in understanding them in future either.
Most of us are just interested in the observations or conclusions or applications. Those may involve some thinking but also may not involve any thinking, just blind acceptance of the paper's claims and possible applications.
3) Coding:
Again, deep thinking is only done by a small set of programmers. Like the ones who write kernels, compilers, distributed algorithms, complex libraries.
But most are just passive consumers who read some examples online or ask stackoverflow or reddit for direct answers.
Some even outsource all their coding entirely to gig sites. Not much thinking there except pricing and scheduling.
What's the difference between that and asking an LLM or copying an LLM's answers? At least, the LLMs patiently explain their code, unlike salty SO users!
----
IMO, most people weren't doing much thinking even pre-AI.
Post-AI, it's true that some people who did do some thinking may reduce it.
But it's equally true that those people who weren't doing much thinking due to access or language barriers can actually start doing some thinking now with the help of AI.
> I'd say most people most of the time outsourced actual thinking to someone else.
Someone else being human, until now. That may change. That's the whole point!
But I concur with your general point on the upstream production of thinking and knowledge. Indeed, such elite thinkers are those in economic history referred to as the "upper-tail human capital". Terence Tao being one of them giving license to the kind of thinking that accepts AI as a simple tool that is not fundamentally breaking our relationship with technology is what exactly I am protesting.
> But it's equally true that those people who weren't doing much thinking due to access or language barriers can actually start doing some thinking now with the help of AI.
If only we keep thinking that thinking is a comparative advantage of our species, I suppose!
Your comment mistakenly assumes this is the only campaign around. But this is just one among many initiatives and websites. There are campaigns against other US big tech companies on this site itself:
To me, the assumptions in your comment about them and their views seem much more like stories of your own creation, likely without any empirical testing of the reality around you.
Couldn't this antichrist stuff be his sane/rational strategy to manipulate the powerful but religious rightwing people under his sway? Is there evidence to assume he himself is on the verge of some kind of psychosis and not fully in control of his faculties?
I'm not sure battling the Vatican over interpretations of an obscure philosopher who mentored him back when he was an undergrad is the easiest way of winning over the religious right. Most of whom will happily go along with generic arguments about Peter Thiel's portfolio being essential to defeat Communist China and the woke libs. Treating Eliezer Yudkowsky as an irrelevant nutter probably works better on people with all kinds of views on religion and politics than attempting to elevate him to the status of antichrist
OpenAI is ethically the type of company that will censor. But this single example doesn't outright support a hypothesis of malice.
There may be non-malicious reasons as well.
If the interface you're using does not include search engine results, the answer seems reasonable and non-malicious.
Or if search engines are giving conflicting information or showing only shady sources, the answer seems reasonable.
Maybe try to find some pattern in answers to diverse questions about US elections and parties.
Not most. But I have the impression that Rust has a cultish fan club in general (with typical problems of cults, like downvoting critics of the language or the cultishness), and some of its thought leaders (cult leaders?) seem to be active here.
Not unique to Rust. I agree with the other comment about similar cyclical fads.
I think this is the main reason. Dedicated group acting in coordination to comment, post, upvote, downvote is enough to build influence and some type of seeming consensus in a voting based forum like this.
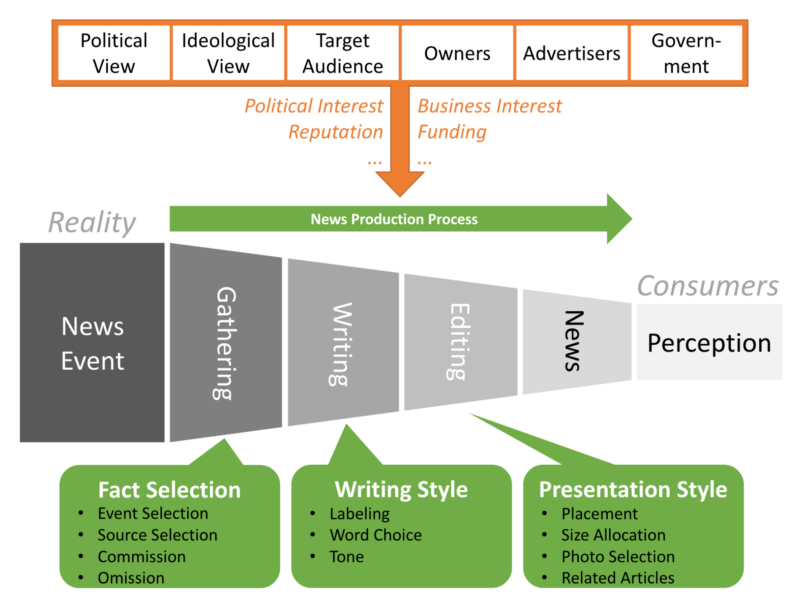
News reporters and editors have their biases. Book authors have their biases. Scientists and research papers have their biases. Search engines have their biases. Google too.
All human-created systems have biases shaped by the environments, social norms, education, traditions, etc. of their creators and managers.
So, the concepts of "objective truth" and "reputable" need to be analyzed more critically.
They seem to be labels given to sources we have learned to trust by habit. Some people trust newspapers over TV. Some people trust some newspapers over other newspapers. All of it often on emotional grounds of agreeability with our own biases. Then we seem to post-rationalize this emotion of agreeability using terms like "objective truth" and "reputable".
Is Google search engine that leads to NY Times or Fox News or Wikipedia and makes us manually choose sources as per our biases "better" than Google's Gemini engine that summarizes content from all the above sources and gives an average answer? (Note: "average answer" as of current versions; in future, its training too may be explicitly biased, like Grok and DeepSeek did).
Perhaps we can start using terms like "human sources of information" versus "AI sources of information" and get rid of the contentious terms.
Then critically analyze whether one set of sources is better than the other, or they complement each other.
Whilst chasing after "objective truth" is a philosophical problem, it's clear that some statements are more correct and true than others.
News articles are often biased, but most of the time, the bias is from the choice of what is reported and choosing specific language to push an interpretation (e.g. reporting road traffic collisions as "accidents" to downplay them or depersonalise them by stating "car hit tree" rather than "car driven into tree"). The problem with some LLM outputs is that it's not just bias, but clearly incorrect such as recommending putting glue onto pizzas.
However, omission and downplaying can also be harmful just like hallucinations. One redeeming quality of LLMs is that we can ask the same LLM to fact check its previous answer and they do tend to correct most of their mistakes themselves. Something we can't do with media sources, and usually don't try either.
LLMs along with existing sources can be good complementary tools for getting even closer to an objective truth than relying on either one by itself.
I disagree as hallucinations can be drastically far more harmful or misleading than bias.
The problem as I see it is that LLMs perform a type of lossy knowledge compression. Also, the data on which they're trained will typically be the biased articles, so they're unlikely to be any better and very likely worse as they will encode the biases. I don't really see LLMs as being complementary tools as they're more of a summation/averaging tool - like comparing an original painting with a heavily compressed JPEG of that painting. (Of course, having access to a huge library of JPEGs is often more useful than just owning a single painting)
> Is Google search engine that leads to NY Times or Fox News or Wikipedia and makes us manually choose sources as per our biases "better" than Google's Gemini engine that summarizes content from all the above sources and gives an average answer?
If you use just any amount of critical thinking, yes. Truth and objectivity are ideals, not practical states. LLMs are a very bad way to come close to this ideal. You may use them as a search interface to give you sources and then examine the sources, but the output directly is a strict degeneration over primary or secondary sources that you judge critically.
> LLMs are a very bad way to come close to this ideal...the output directly is a strict degeneration
I didn't understand the second part but regarding the first...
For me, LLMs are just another source of information with a different UI, analogous to newspapers, TV documentaries, Wikipedia, Google search, YT talks/documentaries, even the majority of informational non-fiction books, and research papers.
Some may consider some subset of these as reputable sources. But in my mind, the same faculties of skepticism, cynicism, distrust, and benefit-of-the-doubt calculus are activated for all of them, including LLM outputs.
So that's one possible answer to your question.
But I suggest communicating this through simple illustrative examples to help your target audience understand the problem.
Abstract terms like primary sources, secondary sources, reputable sources, objective truth, strict degeneration, etc. may not help, especially if they have time or other constraints that make frequent critical examination of sources impractical.
> For me, LLMs are just another source of information with a different UI, analogous to newspapers, TV documentaries, Wikipedia, Google search, YT talks/documentaries, even the majority of informational non-fiction books, and research papers.
LLM just distils information from those sources and is therefore always a second hand source at best, and a liar at worst. Humans can collect real world data and write about their findings, LLM cannot do that, that makes LLM strictly worse than the best human sources.
The nature of the source, whether primary or secondary or tertiary, does not automatically imply anything about their biases. Even a primary research paper on a novel topic may be biased or wrong.
I agree that LLMs can't collect real world data and write about their findings. But that's true about most human sources too, isn't it? Except primary novel researchers or investigations or philosophies, what is original? Most human-written information is also secondary or lower.
The "best human sources" does not imply "ALL human sources."
> For me, LLMs are just another source of information with a different UI, analogous to newspapers, TV documentaries, Wikipedia, Google search, YT talks/documentaries, even the majority of informational non-fiction books, and research papers.
With all due respect (not trying to be offensive at all) but this is insane to me.
All those sources of information you cited have a million incentives to provide fairly correct and checked information. But probably more importantly, they have even more incentives to NOT provide false information. At a minimum, their careers, reputation, recurring work, brand, etc... is on the line.
An LLM has zero incentives to provide you with true information, beyond a couple of md files with instructions. If it gets it wrong, there is zero accountability, just an -oh, you're absolutely right- response and move on.
I agree there is a lot of human bias in the world, but surely we can't even put in the same order of magnitude both types of biases!
The mere fact that editing is applied to newspapers, documentaries, or Wikipedia does not imply they become closer to the objective truth or free of omissions after the edits. Indeed, the edits may go the other way to align with vested business or political biases or personal fears of the editors or their management.
As for research papers, I agree that the peer review process makes them more much more self-correcting toward the objective truth, compared to the other formats. Nonetheless, it's well-known that academic research is far from perfect due to publication pressures, funding/grants, reproducibility crises, various biases (for example, political pressure in humanities fields).
Needless condescension and wrong assumption. No wonder so many people and students nowadays prefer answers (and even counseling) from LLMs instead of other people.
> but the absence of an editor or peer reviewer also does not make it better.
I don't see how disputing up the claim that LLMs and books, newspapers, etc are equitable sources of information is a strawman. I look forward to your erudite vernacular which will not deal with the substance of my comment.
Ironically, this is the classic bias of "bothsiding" the issue. When one side is clearly wrong, just sprinkle in some "look, the others are doing something bad, which means they are equally wrong". A basic lesson from the propaganda manual.
I know what you mean, and I realize some of the things I've written sound similar to what various rightwing commentators tend to say (e.g.: "concept of objective truth must be analyzed critically.")
But my motive is very different. It's not to deny any kind of injustice or misinformation by hiding behind inherent uncertainties and bothsidesism. I'm not in favor of giving the benefit of the doubt to the powerful by default - that's already happening a lot under our current system of so-called "reputable sources."
Instead, I'm saying that this kind of injustice masking and misinformation may also be present in the very sources that ethical people may have come to trust by habit.
My suggestion is to use the power of LLMs as complementary tools to become even more rational and critical, in the direction of even better ethics and justice.
I'm advocating for even more skepticism of the powerful, not less. I'm advocating the approach Betrand Russell recommended for acting under uncertainties, and feel LLMs can be useful complementary tools for doing just that.
This is an insightful comment, but I feel like you omit the fact that LLMs often give out verifiably false information that can hurt the user or other people.
It is true that this also happens on the Internet, but! When I encounter an article about a topic and it is clearly LLM generated, I can expect it doesn't contain much valuable information, only rehashes of what is already out there. On the other hand, when it is clearly written by a human, I can expect to learn something new, even though the author has some bias.
It's wrong to assume incompetence, which is what you did to a comment which displays much deeper chain of thought about the subject. A more proper way of doing it would be to reflect over your own opinions and critically assess them, as the comment points that out. To be more specific, what makes you think that the person you're replying to is not aware that LLMs can give false information, and is not taking that into account?
You're right that LLMs do spit out false information or wrong knowledge. I've experienced them too.
But a redeeming quality is that we can ask the same LLM to fact check its own answer step by step in real time with little effort. They often identify their own hallucinations and reduce the probability of retaining that mistake in the rest of the conversation.
This isn't easy with human sources. The effort to fact check without LLMs or ask the sources to fact check themselves are both higher. So it's often not done at all.
We also often ignore subtle but very common biases in human media sources [1], which create other types of errors like omissions and euphemisms which have been no less harmful than LLM hallucinations. The case of the Iraqi WMDs of Iraq and the NYT's dispersal of that disinfo, for example [2].
Regarding valuable information and rehashing, we probably shouldn't equate between all the things LLMs can do, and AI-generated articles. The quality of the latter may be entirely due to the lack of interest, attention, and cost concerns of whoever generated the article. Anecdotally, I have often found valuable knowledge and obscure connections by using deep research tools with careful prompts.
Lastly, if you're frequently finding something new from human-written sources, and LLMs are being trained on most of those same sources, isn't it logical that the latter will also likely output that same information?
This is why I feel human and AI sources are probably best used as complementary tools. Neither set of sources are perfect but each set has its strengths. By using both, we can get closer to an objective truth than using only one of them.
The effort to fact check with LLMs is also high. Here's one from a few days ago.
Someone used AI to generate an image in the style of a Charles Schulz Peanuts cartoon.
Someone else observed that there were 5 fingers on the characters, and quoted as Google AI as saying “Charlie Brown, along with other Peanuts characters, is generally depicted with four fingers on each hand (three fingers and one thumb) ...”
Fact checking this with human sources is easy and not ambiguous. While LLMs are being trained that many cartoon characters only have a thumb and three fingers - it is a trope for a reason - so isn't it logical for LLMs to give the wrong answer for a comic where the human characters are actually drawn with 5 fingers?
My experience with LLMs is they keep getting things wrong, when details matter.
Do you ask the LLM to fact check everything? (In which case, why isn't that part of the standard prompt?) Or do you only ask to fact check things where you are unsure about the answer? (In which case, is it the algorithm telling you what you want to hear?) When do you stop the fact checking?
Exactly the same calculus as fact checking anything else from any other source. What are the social/economic/ethical consequences to me if the answer is wrong or inaccurate or incomplete? How much time do I have to check? How thorough should I be?
I imagine this calculus isn't really that different for most people. Or is it?
As for your example, I believe it. But I also feel it's a rather outlier example involving image comprehension of an obscure factoid. That isn't typical of how I use LLMs which is mostly as text-based question answering engines and not what I had in mind when writing the comment.
I guess LLMs for image comprehension need a much higher level of skepticism.
Well, in my case going to a Peanuts comic and looking at hands was pretty easy, and didn't involve any questions about negative environment or labor consequences, the massive hammering of web sites to gather data, centralization of power, and the like.
Like, "!w Peanuts" in my search bar, look at the image, and count fingers.
"a rather outlier example"
You wrote that you use AI to find "obscure connections" - aren't those all by definition outliers?
"mostly as text-based question"
I just now asked Google AI "how many fingers are on charlie brown's hand?"
It replied "In the Peanuts comic strip, Charlie Brown and the rest of the gang are traditionally drawn with four fingers (or three fingers and a thumb) on each hand."
No image comprehension, exactly as you had in mind. And completely false.
HN isn't showing me a reply option for your latest comment, so I'll reply here instead.
Just to clarify, I used plain Google search not Google AI mode. And opened search results which seemed "reputable," without knowing anything much about Peanuts cartoon or cartooning.
I had no idea at all about archive.org having it and didn't see it listed in the first two pages of search results.
I still find it confusing, especially given what the Variety.com link says which doesn't mention orientation. If the acceptable explanation for 4 vs 5 is orientation, why is it wrong when the AI generated 4 fingers? Does it not match the rest of the orientation?
Anyway, I'm not sure where this leaves LLMs. I'll explore image capabilities when I get some opportunity and keep your comment in mind.
The comment about using Google was more a curiosity. I hadn't seen the Variety link until yesterday, when I went to Google to reproduce the answer to verify it was from a text query, not an image query. Both Google AI and one of the top answers included that Variety link. When you mentioned it again, it strongly suggested you were using Google as your primary search method.
I think the right way to interpret the Variety link is that it's a single paragraph about trying to capture the feel of the comic using 3D software. As you saw from Charlie Brown holding a baseball, Shulz didn't go for a realistic look, but still conveys the sense of grasping. Modeling all five fingers all the time would not give the movie the right feel.
I wonder now if Google AI incorporates text from the top results into its answer.
"why is it wrong when the AI generated 4 fingers?"
The original discussion was when person X used AI to generate a image "in the style f Charles Shulz" where the Peanuts characters had 5 fingers, then person Y noted the use of 5 fingers instead of the 4 which is common in comics and cartoon, and quoted Google AI as saying Peanuts was traditionally drawn with 4 fingers.
I yesterday verified that Google AI would generate the same wrong answer with a text query, so it was not an image interpretation issue.
FWIW, after looking at a few hundred Peanuts cartoons, I can confidently say the AI generated image was not in the style of Schulz. The generated fingers were too realistic, and the background too complicated and detailed. :)
This for me is another example of why using primary sources should be the first thing to consider when fact checking - not LLMs (my experience is they are horrible at details), and not secondary sources (which have their own biases).
Not everything has easily-accessed primary sources, but many do. I think it's all too easy to fall into the trap of accepting the LLM answer because it feels right and is easy to generate. At https://freethoughtblogs.com/stderr/2025/01/18/ai-art-just-r... you'll see someone asked about which river Marbot swam across to spy on the enemy camp. It replied "Elbe". Then I did a text search of an English translation of the book and found he used a boat to cross the Danube to spy on the enemy camp, and he swam into freezing waters to save an enemy soldier.
Again, do you ask the LLM to fact check itself every single time? If that's useful, why isn't it built into the prompt? Or, if you are supposed to double-check the LLM yourself, why would you consult a secondary source if the primary source is so easy to find and search? And in that case, why not just use the primary source?
Further, if you aren't in the habit of checking primary sources then you won't have the experience to know how to find and check primary sources.
Even as a human, I find whatever sources Google shows to be inconsistent. I can't give any confident answer about the number of fingers. I think the answer is actually "4 sometimes and 5 other times."
So I'm not sure how much LLMs can handle this kind of inconsistency between "reputable" visual sources and text sources, nor how representative this example is.
> “The rig would automatically move the features around so it would match the way Charles Schulz drew the character,” Heller says....In some drawings, Charlie Brown has just three fingers, while in others, he has five
Anyway this wasn't the type of obscure connections I was referring to though I can understand you interpreting it that way.
Personally I think this example supports what I said about "reputable sources." They can't be blindly trusted either because they may be inconsistent with each other and which one we choose to believe (Reddit.com or TVTropes.com or Variety.com) becomes entirely subjective.
Your first link was cited in the 2nd half of Google AI's answer, and one of the top Google answers, so I think you are using Google as your information source.
The large majority of the images you link to show kids with 5 fingers, as well as 5-fingered baseball gloves. The cases of four fingers are due to orientation.
Your "1." also shows Marcie with five fingers. You see Charlie Brown with 4 fingers because he's holding a baseball. In 2. he's also holding a baseball. You would not see 5 fingers on one side because doing so would look strange.
In your unlabeled "0." there are plenty of kids with 5 fingers. There are some with fewer, but they are holding things or drawn in way to suggest we are seeing the hand from the side.
I don't understand your hesitancy. Your own samples should be enough for you to decisively conclude that the Google AI's claim that Peanuts was "traditionally drawn with four fingers (or three fingers and a thumb) on each hand" is wrong. If not, it sure seems like you trust Google AI over your own eyes. Why are you so hesitant to agree?
My point is that you don't need to consult secondary sources when the primary sources are easily available.
When this came up a few days ago, I spot checked the complete works of Peanuts, from a collection on archive.org at https://archive.org/details/peanutscomics19502000/Volume%201... . The consistent pattern across the nearly 50 years of Peanuts is the kids have five fingers unless obscured by orientation or objects.
You can do that yourself, and triple-check that Google AI's answer is clearly wrong.
Thus, I think it's a good example of how fact checking with LLMs can lead people astray, and the large negative externalities I mentioned combined with its well-known tendencies to make incorrect statements make it a very poor starting point when the primary source, at least in this case, is so easy to access.
If most of the sources are wrong, and LLMs are being trained on those, isn't it logical that the latter will also likely output that same wrong information?
When do you know if most of the sources are wrong, unless you yourself know most of the sources are wrong?
We were facing the same challenge and had to build something that delivers consistent, near-99.99% accuracy — it’s called LiveFix (livefix.ai).
It’s a drop-in proxy between your app and your LLM. Every response is corrected during generation, not after. One API call. No retries.
Each response returns with a trust status: *verified*, *needs_review*, or *requires_human* — no silent failures.
We’re seeing a ~99% pass rate across thousands of clinical documents. Budget models are matching premium-level accuracy at ~75% lower cost. Benchmarked against top-tier budget and frontier models, with performance improving across the board — benchmarks are published.
> But a redeeming quality is that we can ask the same LLM to fact check its own answer step by step in real time with little effort. They often identify their own hallucinations and reduce the probability of retaining that mistake in the rest of the conversation.
It is not really a redeeming quality of LLM. It falls apart because if you want to properly fact check an LLM, you have to make yourself aquinted on human-generated contents- facts, arguments, and biases from "both sides" when it comes to complex topics. What's the point of relying on LLM if you are having to do that anyways to reach objective truth?
Case in point- someone in a tweet used LOTR reference to the US/Israel vs Iran conflict, equating Iran to Sauron and US/Israel to the good guys. I asked Grok if that is a valid parallel. In the beginning, Grok agreed with the tweet. Then I had to point out how Iran has been weakened by decades of sanctions by US, it started to agree that US might be more like Sauron's army. Grok time and again used Islamic regime's treatment of it's own people as an evidence that Iran might be the evil force, but when I cited Israel's treatment of other Arab civilians, or the Shah regime's treatment of it's own people back in the day and it's allegience to US, it changed it's stance again. When I cited it's influence on US policies, Grok even admitted that Israel might be the Wormtongue here.
This also shows how LLM totally falls apart as a way to reach objective truth, because you can manipulate it to say anything that you want. I could easily present evidence from my own research and make Grok reach completely opposite conclusions.
Gemini (currently) gave this reasonable and unbiased answer that challenges both pro-US/Israeli and pro-Iranian biases.
It's also a good point for the OP - when selecting an LLM, ask the people they're dealing with to ask 2-3 LLMs. It's much faster (and cheaper!) than reading about a complex geopolitical issue (that may not matter to them enough to spend a lot of money on books and research papers) while at the same time correcting common biases on all sides.
----------
> Someone said in the ongoing US/Israel vs. Iran conflict, Iran is like Sauron from the Lord of the Rings and US/Israel are like the good guys. Is this a valid parallel given the history of US, Israel, and Iranian regimes?"
Comparing real-world geopolitical conflicts to fictional narratives like The Lord of the Rings is a common rhetorical device used to frame complex situations in terms of absolute good versus absolute evil. However, determining whether this is a "valid" parallel depends heavily on one's political perspective, as real-world geopolitics rarely aligns perfectly with the clear-cut morality of fantasy literature.
> Historians, international relations scholars, and observers generally view such analogies as overly simplistic, as the histories of the United States, Israel, and Iran are marked by competing interests, shifting alliances, and moral complexities.
Here is a breakdown of how different perspectives view this analogy:
*The Perspective Aligning with the Analogy*
Those who support the analogy framing Iran as the villain ("Sauron") and the US and Israel as the "good guys" often point to the current actions and rhetoric of the Iranian government:
* *Regional Destabilization:* The Iranian government heavily funds and arms the "Axis of Resistance," a network of proxy militias including Hezbollah in Lebanon, Hamas in Gaza, and the Houthis in Yemen. These groups have engaged in prolonged armed conflicts with Israel and targeted international shipping.
* *Existential Rhetoric:* The leadership of the Islamic Republic of Iran frequently uses rhetoric calling for the destruction of Israel and the downfall of the United States (often referring to them as the "Little Satan" and the "Great Satan").
* *Human Rights:* Iran's theocratic regime is heavily criticized by international human rights organizations for its severe suppression of internal dissent, lack of democratic freedoms, and treatment of women.
* From this viewpoint, the US and Israel are democratic nations acting defensively to protect their citizens, regional stability, and global security from an aggressive, authoritarian regime seeking regional domination and nuclear capabilities.
*The Perspective Challenging the Analogy*
Critics of this analogy argue that casting the US and Israel as flawless "good guys" and Iran as an irredeemable evil ignores significant historical context and the controversial actions of Western and Israeli governments:
* *Historical Interventions:* Critics point to the 1953 Iranian coup d'état, in which the US and UK intelligence agencies orchestrated the overthrow of Iran’s democratically elected Prime Minister, Mohammad Mosaddegh, to reinstate the authoritarian Shah. This event deeply scarred the Iranian psyche and laid the groundwork for the 1979 Islamic Revolution and the regime's current anti-Western stance.
* *US Foreign Policy:* Observers critical of the US point to its history of military interventions in the Middle East—such as the 2003 invasion of Iraq—which resulted in hundreds of thousands of civilian casualties and regional destabilization.
* *The Israeli-Palestinian Conflict:* Critics of Israel point to the prolonged military occupation of Palestinian territories, the expansion of settlements, and the high civilian death tolls in conflicts like the ongoing war in Gaza. From the perspective of Iran and many in the Global South, Israel is viewed as an oppressive or colonial force, and the US as its imperial enabler.
* From this viewpoint, Iran frames itself not as an aggressor, but as the leader of a resistance movement pushing back against Western hegemony and defending marginalized populations in the Middle East.
*The Analytical Perspective*
In The Lord of the Rings, Sauron is a localized, supernatural force of pure malice with no valid grievances, while the coalition fighting him represents the preservation of life and freedom.
Geopolitical analysts generally avoid mapping this binary onto international relations. Instead, they view the US/Israel vs. Iran conflict through the lens of realpolitik and state interests. In reality, all states involved are acting to secure their own survival, project regional power, and protect their economic and security interests. While individuals and governments may hold strong moral convictions about which side is justified, framing the long, deeply intertwined history of these nations as a simple battle between absolute good and absolute evil omits the historical grievances and civilian suffering experienced on all sides.
> Is Google search engine that leads to NY Times or Fox News or Wikipedia and makes us manually choose sources as per our biases "better" than Google's Gemini engine that summarizes content from all the above sources and gives an average answer?
That's not what Google's AI mode does, though. It presents a bunch of sources along the answer, but in my experience, the sources in many cases don't actually back up the claims generated by the LLM.
I felt the question is based on some shaky assumptions that may lead to a poor answer.
Since the OP trusts humans more by default, is it a problem if I point out those assumptions? Ask HN need not become another SO.
I did explain the weaknesses of both LLMs and "reputable sources" and suggested people use them as complementary tools. I also suggested using the convenient self-fact-check feature of LLMs, something we can't do as easily with traditional sources.
> I did explain the weaknesses of both LLMs and "reputable sources" and suggested people use them as complementary tools. I also suggested using the convenient self-fact-check feature of LLMs, something we can't do as easily with traditional sources.
That just explains how to find facts for yourself, not how to deal with a person who trust LLM outputs. So you still haven't answered the question.
> Since the OP trusts humans more by default
OP never said that. OP said there is a problem with people trusting LLM instead of doing proper research and finding good sources, you explaining how to do proper research and finding good sources doesn't have anything to do with the question.
I gave suggestions that OP can pass on to the people they have to deal with. I didn't realize it has to be pointed out explicitly SO-style to some people.
OP implies human sources are the "good sources" or "reputable sources." This kind of confusion is exactly why I suggested using better terms than "reputable sources" or in your case "good sources."
> OP implies human sources are the "good sources" or "reputable sources."
No OP did not do that, nowhere did OP mention human sources. When I search the internet I don't just find human sources, I also find automatically generated data graphs and maps and such, those are also good sources of data. If I had to choose between a map from Google maps and a map from an LLM I'd trust the map from google maps any day.
Are you saying there are data graphs that don't have humans in the chain? If so, what came up with the data and the tools to generate those graphs? And how do you decide which data and graph to trust? What exactly makes them "good sources"?
> If I had to choose between a map from Google maps
I would too. But Google Maps relies on local 3d party survey companies that use people, manual GIS tools, and image recognition AI. How do you know they don't have any mistakes in them? In fact, I live in a country where local area names are frequently misspelled on Google Maps, and reverse geocoding gives misleading addresses.
I feel my point that all these "reputable sources" or "good sources" have biases (and mistakes) still stands.
I must also point out that the 3 concrete examples given against my replies all involved visual content like graphs, maps, Peanuts cartoons, etc. But my comments were written with the typical text-based usage for QA in mind. I don't know if LLMs can fact-check map imagery or data graphs (probably not, but I've never tried). It's just not the kind of thing I'd ever use LLMs for, to begin with.
> I feel my point that all these "reputable sources" or "good sources" have biases (and mistakes) still stands.
That does not contend with the premise. The premise is not that reputable sources are perfect or form objective truth.
The premise is that when you do not have the time to investigate something closer reputable sources are much more likely to be close to the truth than LLMs that are trained on these reputable sources as well as unreputable sources and just mimick these training source material thereby obscuring the source of information and introducing hallucinations.
When you have the time to investigate information, primary sources and reputable secondary sources allow you to more easily trace information and judge its validity. LLMs by their nonpredictable nature hinder this.
Thesis: "A is better than B"
Argument: "A is flawed"
The argument does not engage with or weakens the thesis.
{kind=link}
{kind=link}
{kind=link}
Well, I happen to use it everyday. I honestly don't know what exactly is "terrible/horrible/awful" about it. I'm neutral about its UX - neither memorable nor despicable. It may be missed if the new app's UX turns out to be worse on whatever metrics you're using.
reply