AFAIK "orbital data centers" are a bunch of nonsense.
1. GPUs create heat. There's no efficient way to get rid of the heat in space (vacuum is an insulator).
2. Die-shrink makes modern processors and memory more and more susceptible to radiation; shielding is possible, but adds cost + mass (which adds cost)
Yes! I'd be totally happy with today's sonnet 4.6 if I could run it locally.
If you can forgive the obviously-AI-generated writing, [CPUs Aren't Dead](https://seqpu.com/CPUsArentDead) makes an interesting point on AI progress: Google's latest, smallest Gemma model (Gemma 4 E2B), which can run on a cell phone, outperforms GPT-3.5-turbo.
Granted, this factoid is based on `MT-Bench` performance, a benchmark from 2023 which I assume to be both fully saturated and leaked into the training data for modern LLMs.
However, cross-referencing [Artificial Analysis' Intelligence Index](https://artificialanalysis.ai/models?models=gemma-4-e2b-non-...) suggests that indeed the latest 2B open-weights models are capable of matching or beating 175B models from 3-4 years ago.
Perhaps more impressive, [Gemma 4 E4B matches or beats GPT-4o](https://artificialanalysis.ai/models?models=gemma-4-e4b%2Cge...) on many benchmarks.
If this trend continues, perhaps we'll have the capabilities of today's best models available to reasonably run on our laptops!
The title is a misdirection. The token counts may be higher, but the cost-per-task may not be for a given intelligence level. Need to wait to see Artificial Analysis' Intelligence Index run for this, or some other independent per-task cost analysis.
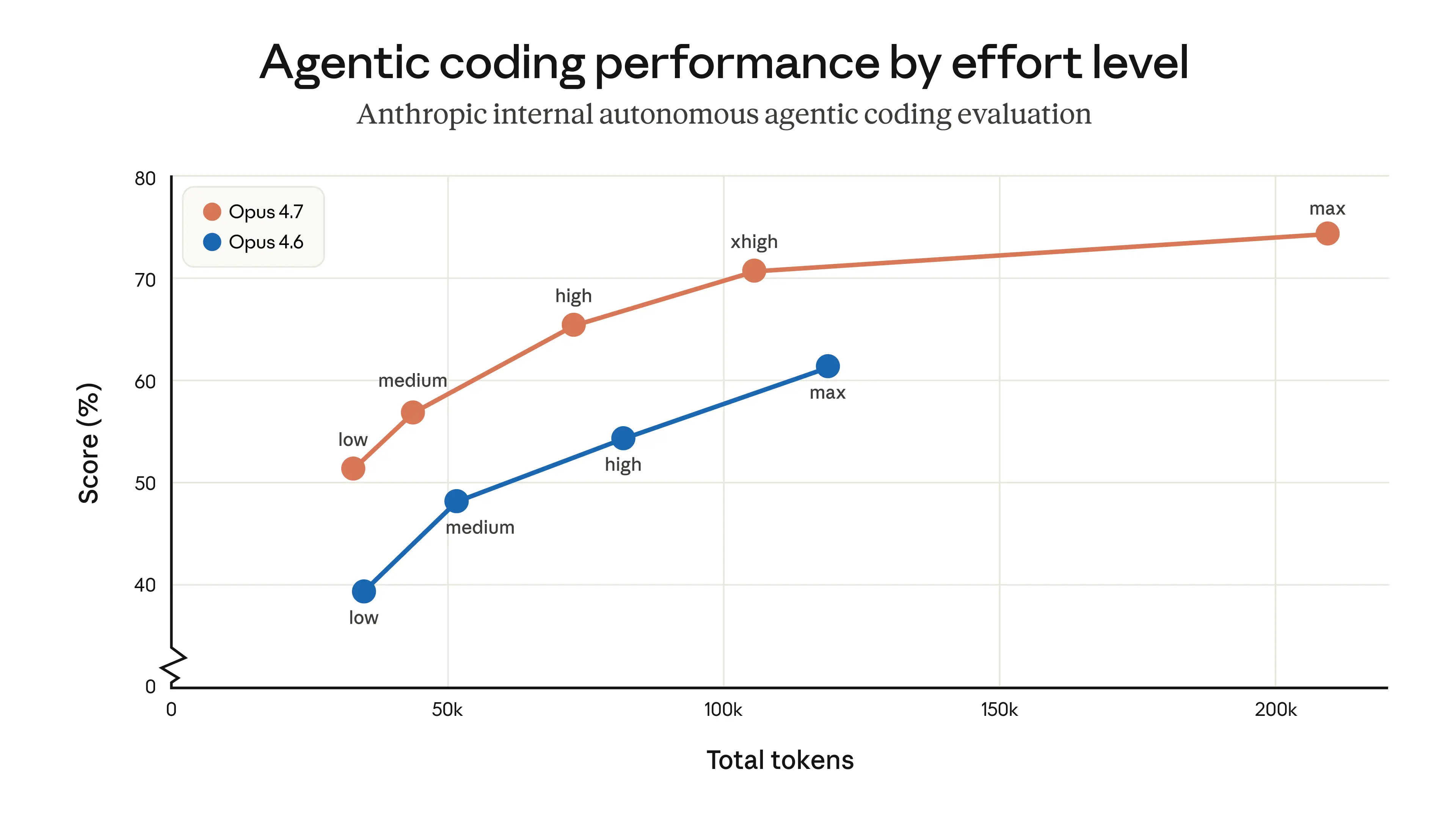
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6.
I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.
I ran an internal (oil and gas focused) benchmark yesterday and found Opus 4.7 was 50% cheaper than Opus 4.6, driven by significantly fewer output tokens for reasoning. It also scored 80% (vs. 60%).
yep, ran a controlled experiment on 28 tasks comparing old opus 4.6 vs new opus 4.6 vs 4.7, and found that 4.7 is comparable in cost to old 4.6, and ~20% more expensive then new 4.6 (because new 4.6 is thinking less)
A fun conspiracy theory I have is that Mythos isn’t actually dangerous in any serious sense. They just can’t reliably serve a 10T model. So they have to make up a reason to limit customers.
(Submitted title was "Claude Opus 4.7 costs 20–30% more per session". We've since changed it to a (more neutral) version of what the article's title says.)
I think it's time to have previous titles show as a edit * icon that can show the previous title.
This is not the first time where the more neutral (which imo is better) has caused me to be confused why everyone is saying something different in the comments.
That's probably too much ceremony for HN but petercooper made a really nice HN title edit tracker which is probably still running. Let me see if I can dig it up for you...
im running some experiments on this but based on what i have seen on my own personal data - I dont think this is true
"given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.”
Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that
Very unlikely that the article is wrong. the 4.7 intelligence bump is not that big, plus most of the token spend is in inputs/tool calls etc, much of which won't change even with this bump.
My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!)
If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token).
Write a response to this website: https://stopsloppypasta.ai/
Make sure to avoid all common AI-isms and not make it look like it was written by AI. Include mistakes, don't use em-dashes, don't use common AI phrases, etc. Plan out what would normally look like AI first, and avoid those things. Also don't make it a narrative, make it one paragraph that is simple and to the point. Try to have a snarky attitude.
Oh, I 100% acknowledge the site itself was LLM generated. I'm not a web designer, so I needed a lot of help making a visually appealing site, even if that design language is at this point LLM trope.
However, the essay and the guidelines were all human-written!
by "human-written" do you mean you just used LLM to help the grammar and spelling and formatting and to think up some use cases but its entirely "my own words"?
Hits you in the first row of buttons with the classic gen-AI slop "Why It Matters".
So trace* through ninerealmlabs and ahgraber and sure enough:
I used AI:
- to help build this website.
- to help generate examples of sloppypasta
based on my original guidance
- to proofread and review the human-written
copy to provide a critical review
- to improve my arguments and ensure clarity.
Kudos for being forthright.
---
* Turns out clicking "Open Source" bottom right gets there faster!
I talked myself in circles on that "why it matters" heading but ultimately couldn't come up with a better one. "The problem" has similar ai-slop feel, and "the rant" // "the rules" didn't really evoke the feeling I wanted.
It's not difficult to create a visually appealing website. You don't have to be a designer. Many of us here aren't designers and have beautiful sites. Have you tried doing it yourself?
I acknowledge that those likely to copypaste slop aren't likely to find this article themselves, but I built the page to be shared or guide discussions around etiquette like nohello.net or dontasktoask.com. IMO a common understanding of AI etiquette would provide social pressure to halt some of these behaviors.
I honestly don't mind someone else's AI as long as I can trust it/them. One problem I have with sloppypasta specifically is that it reads as raw LLM output and the user isn't transparent about how they worked with the AI or what they verified. "ChatGPT says" isn't enough; for me to avoid inheriting a verification burden, I'd also need to understand what they were prompting for, if they iterated with the AI, and if/what/how they validated.
(the other problem is that dumping a multi-paragraph response in the midst of a chat thread is just obnoxious, but that's true even if its artisanal human-written text)
Good point: RTFM and (wall of slop) are two ways of telling someone that responding to them is not worth your time that are both ruder and more time-consuming than simply saying nothing. Explaining the culture of RTFM, i.e. "if there was any way you could possibly have found the answer otherwise, you should never have asked the question" to non-tech friends usually results in disbelief.
But the slop-wall is even worse, as it wastes the questioner's time in figuring out that they're just getting slop. At least RTFM is efficient.
I think you will find you will get farther by offloading this unpleasantness to an AI and open sourcing it rather than teaching etiquette to the internet, a place not known for its decency.
There’s a certain very satisfying force to turning something into a static website that you can point people at. The Internet equivalent of “don’t make me tap the sign”; especially in an era of AI-slop.
{kind=link}
reply