Just to set some context - this is being driven by Quansight which is led by Travis Oliphant, who united Numeric and Numarray to create NumPy many years ago which lead to the entire python data science ecosystem as we know it. Yes it's ambitious, and they may not succeed, but it's not their first barbecue. Unifying communities and APIs is something they're good at.
For some context on why this matters, if you're writing a library (like sklearn) and you want to support multiple array types, you might need to do stuff like
if isinstance(x, ndarray):
...
elif isinstance(x, other_array):
...
In the most ideal case having the standard means that scientific libraries can support all conforming implementations by default. Then sklearn would automatically support cupy/numpy/dask/jax/mxnet/pytorch/tensorflow arrays. Multiply that by all the scientific libraries and the effect is pretty profound.
If arrays are standardized, we may even see a future where they end up being in the stdlib, while libs like numpy, dask, etc. will mostly provide tooling to work with them.
This would be a huge deal, allowing pure Python libs to suddenly exist for a whole lot of things like image/video manipulation, advanced stats, and so on, without requiring compiled extensions.
I love numpy, but having to install the 100Mo beast is overkill for a lot of use cases. Not to mention restricted environments where you can't.
Well, one can dream, no?
Imagine having a numpy-like array as a primitive. Suddenly you can make the case for a K/J-like DSL embedded in it like regexes are for text. Suddenly Python-fast enough perfs are getting an order of magnitude higher. Suddenly you get a powerful shared buffer for multiprocessing.
I suppose this can be compared to standardising SQL. However that has ended up with a least common denominator of simple operations and dozens of specialised dialects. Better than before the standard but certainly not great and tons of engineering has gone into cross dialect facades.
Granted I haven't thought as long or as hard as the authors but I wonder if there are easier ways to go about this:
a) something akin to slf4j or one of the many unifying facades in java
b) standardising the data structures/formats. eg Arrow has done quite a good job positioning itself as a data lingua franca and has compute primitives.
I think this might be a bit premature. For the bulk of these tools (pandas/numpy/tensorflow/torch), most of their users have probably been using them for 3-5 years max.
A universal API standard is a nice idea, but I don't know that the ecosystem has been around long enough to justify this effort.
Given the asynchronous nature of consortiums though, maybe this exactly the right time to start talking about this.
This is about creating a standard for array computing in Python which has been around for more than 20 years. NumPy (which has been a de facto standard) has been around for 14 years and was based on Numeric which was around for 10 years before that. Pandas has been around almost 10 years now. The parts of the standard that are clear and will emerge are the parts that have been around and used by sufficient numbers for at least a decade.
This actually strikes me as a huuuge waste of effort. I work with every one of the different technologies they mention every day.
The differences and idiosyncrasies are truly, truly not a big deal and really what you want is to allow different library maintainers to do it all differently and just build your own adapters over top of them.
This allows library developers to worry about narrow use cases and have their own separate processes to introduce breaking changes and features that deal with extreme specifics like GPU or TPU interop, heterogeneous distributed backed arrays, jagged arrays, etc. etc.
Let a thousand flowers blossom and a thousand different Python array and record APIs contend.
End users can write their own adapters to mollify irregularities between them, possibly writing different adapters on a case by case basis.
If any “standard” adapters gain popularity as open source projects, great - but don’t try to bake that in from an RFC point of view into the array & data structure libraries themselves. Let them be free / whatever they want to be. That diversity of API approach is super valuable and easily mollified by your own custom adapter logic.
Bias warning --- I'm part of the group doing this work. For an end-user, your arguments are fine. A single developer or team can indeed use whatever tool they want and adapt their code without too much difficulty.
The real challenge comes, however, as you try to build an ecosystem of libraries on top of multiple different APIs. You end up reinventing the wheel or struggling to maintain multiple versions of the same library.
Some cooperation is immensely helpful at the lowest level, and we hope ultimately to be helpful to the different tool builders in providing information and guidance about what is already a standard and agreed upon in the space.
This is not about establishing or forcing behavior. It is about documenting and clarifying best practices that have already emerged as well as potentially giving libraries a way to signal to downstream developers of additional libraries that they adhere to the standard.
I don’t really disagree with most of your points, but what you describe does not sound like it should be a committee with governance rules and member libraries tied to an RFC process.
What you describe sounds like you could just create your own single library like a Swiss army knife that contains adapters to rationalize the semantics if you want, even at the ABI level if truly needed.
Member libraries can do a best effort support for not breaking that adapter library’s way of wrapping them, and/or contribute patches that keeps the adapter in sync with new releases of the library.
This makes the adapter layer become totally opt-in and backported rather than required via consortium membership & RFC governance, and even leaves room for competitor adapter tools to coexist that might do things differently.
Ultimately my concern with a governance model is that it creates political power to compel the member libraries to do things that might go against the needs of their users for the sake of the consortium.
I just don’t see a reason why that’s more valuable than letting all the libraries do their own thing and let users choose or make their own custom adapters.
This example of array APIs is nothing like say overall HTTP protocol or IEEE floating point protocol, which are cases where a governing standard makes sense. This is nothing like that in my opinion.
Do you have any ball bark value you could estimate for the size of a bare bone common array implementation?
I'm dreaming of having basic numpy features in the Python stlib, but numpy is so huge, and I have no idea how much of it is the array itself, and how much are all the tooling around it.
So what would you have libraries like scikits-learn do? Support half a dozen array APIs until a 7th array implementation comes around? Support one, and force users to litter adapters everywhere and (often poorly) reinvent the wheel?
I'd very much welcome a unified array API initiative. It's been accomplished in Julia and it's incredibly empowering.
The fact that today you have to special case functions because the various array types are only loosely compatible is a nightmare, not a benefit.
Personally, I like how the Julia ecosystem coalesced around a Tables.jl package that gives some consistency to tabular data packages that choose to implement it. Row-oriented or column-oriented, doesn't matter! Using Tables.jl they can be interchangeable.
Perhaps a more direct Julia analogy would be the built-in AbstractArray interface.
There is simply no question of how (to use their example) `mean(::CuArray; dims)` should work, it not only follows Base's notation, but extends the same `Statistics.mean` function, so that exotic arrays can be passed to packages written before the package defining them existed.
There’s a huge difference between “I personally like it when some libraries choose to adhere to a convention” vs “let’s bake this into every tool with a wide, bureaucratic shared RFC process.”
But I don't think people are forced into following right? There's still choice. But if I was developing something in Python, I would rather join than not join.
I’m saying as a consumer of these libraries, I don’t want joiners, I want lots of different APIs that make different trade-offs for each use case, and I will write (or use) adapters if I need to (that’s my responsibility as a consumer).
Just because I personally either do or do not get some value out of a shared API standard doesn’t mean you do or do not, so personal feelings of what one likes need to be set aside, so the service boundary is at the level of consumers choosing their own adapters and making their own trade-offs.
If lots of libraries sign up, we all lose. Much slower compliance-constrained development cycles, less freedom for libraries to break the shared API contract in ways many users would be super happy to abide for the sake of a faster / better feature. Instead of making these trade-offs library by library, case by case, it’s made for you with standardization compliance as the highest constraint, regardless of the user base for which that does / doesn’t work well.
That’s fair except I’d say even good standards can cause a big slowdown in feature releases, and not everyone values the adherence to the standard as much as the features. It still seems better to just spin out the standard into a set of optional adapters and let library maintainers and users pick their own trade-offs in terms of when to adopt breaking changes, how / whether to smooth over idiosyncrasies across multiple libraries.
Even a good standard has costs and this particular case does not seem like it has good arguments in favor of a wide standard, but many arguments against it.
No, it's easy for library maintainers to offer a compat API in addition to however else they feel they need to differentiate and optimize the interfaces for array operations. People can contribute such APIs directly to libraries once instead of creating many conditionals in every library-utilizing project or requiring yet another dependency on an adapter / facade package that's not kept in sync with the libraries it abstracts.
If a library chooses to implement a spec compatability API, they do that once (optimally, as compared with somebody's hackish adapter facade which has very little comprehension of each library's internals) and everyone else's code doesn't need to have conditionals.
Each of L libraries implements a compat API: O(L)
Each of U library utilizers implements conditionals for every N places arrays are utilized: O(U x N_)
Each of U library utilizers uses the common denominator compat API: O(U)
Where the APIs are compatible anyway, but only the names or order of arguments are different, it sure would be nice to have a standard so you didn't have to look up whether it was count or len or length or size.
Disagree. Those are the super easy cases for me to create my own adapter that does that for me in a way that works for my use case, leaving others free to do it / ignore it at their own discretion, depending on their use cases.
Maybe one person creates various functional wrappers around the array structures to make composition of length or count work in their functional programming design. Someone else created mixins and their own derived classes that solve it with OOP designs, etc etc. Someone else only uses Jax and doesn’t care. Someone else uses infinite streams on top of these and so they never need length or count.
Forcing the same call semantics on all these users doesn’t make sense. Let them build their own abstractions if they need to standardize semantics for their use cases.
As someone who's got some experience with this (but nowhere near as much as you have - I am an amateur), I'd like to strongly disagree with you here.
I find that slightly different APIs between libraries are a real energy-sapper, and having to do the mental gymnastics around them makes little sense to me. Yes, as a super-experienced programmer, you can remember each subtle difference in the syntax of each API, but I think many people find this difficult (me included), and it also leads to problems with code that's written when you've missed something or not used the appropriate part of the API.
One of the strengths of using SciKitLearn for me has been the interoperability across different ML models - by having the same API it means you can try something quickly without having to rewrite code, and can concentrate on the end results, not whether or not you're really telling it what you think you are because you've swapped an element of your pipeline out.
Learning the standard library of Python is a big task; there have been countless times when I've created something which is actually present, but I didn't know it was there, or how to look for it, and then 3 months later seen that utilised in some other code and had a "Why didn't I know that?" moment. I think having non-standard APIs across libraries will lead to this sort of situation, and a lot of reading documentation which would be obviated by the approach outlined in the article.
>Forcing the same call semantics on all these users doesn’t make sense.
I don't understand why not (providing, of course, they are all capable of having whatever is relevant conveyed to them appropriately?
What are the trade-offs that following this standard would involve (other than the delay due to bureaucracy that you mention)?
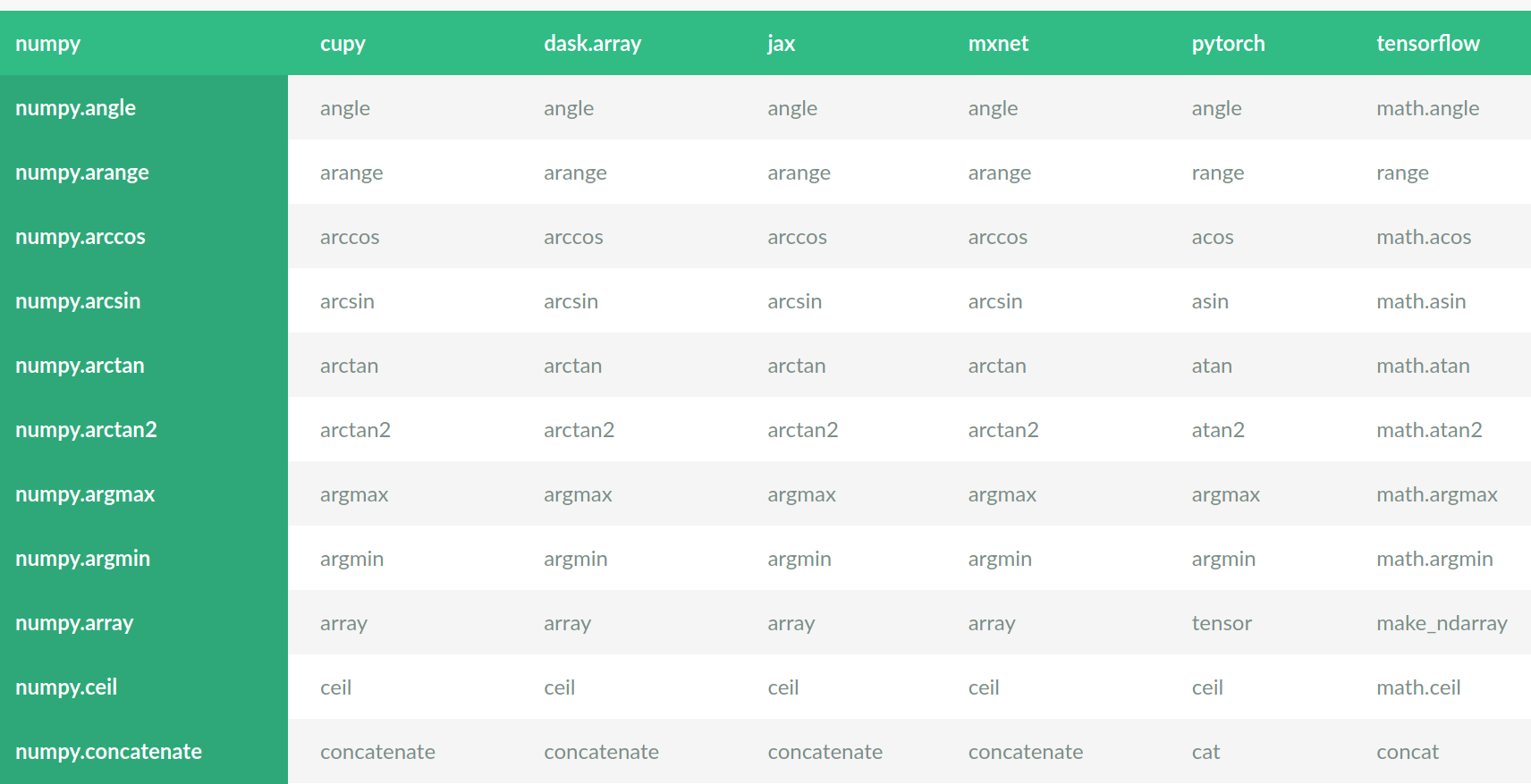
I don't see what is gained by the use of different method/function calls for what are the same method/function, as outlined in the table [1]
I think a scary part of your comment is that since you don’t feel it would impact others use cases and you don’t see why some library might want different semantics, you leap to the conclusion that the burden of proof to prove these things rests with other people.
Given the algorithmic focus of the libraries being targeted, I think the main benefit is if I could do X operations with library A and then use the result to do Y operations with library B. It does seem like that is the intent (if I am not mistaken), so this seems like a worthwhile effort.
One problem with generally using libraries is they work fine until they don't, and once you've been working in one library for a while, all of your support functions, and transformed data are all based around that library's api which makes integrating a new one difficult. This could help with that type of difficulty.
I am so confused. Maybe it's because I'm a part-time self-taught programmer. Are we _calling_ function signatures 'APIs' just so we can speak about the topic of so much diversity in what on the face of it should all be the same implementation? Because my idea of API is the endpoint for a closed system, usually accessed over the wire.
Is this use of the term 'API' canonical or artistic license?
APIs are Application Programming Interfaces, and they have existed long before the web and web services. The article's use of APIs is correct. A really well known example of an API is the C library.
I wonder if this risks ossifying API's at the lowest common denominator. Both the numpy and pamdas API's are far from ideal, see for instance the recent developments towards named tensors.
My Datasette project has given me a slightly different perspective on API standards - at least in terms of things like shared definitions of XML, JSON shapes, RDF schemas etc.
Once you've loaded your data into a SQLite database and put Datasette in front of it, your audience can get the data out in any shape that they like.
That's using a convoluted SQL query to define exactly what I want back in that feed.
The point is: if you have a sufficiently flexible API gateway in front of your data, the people consuming your data can define the "standard" that they want to retrieve it in at runtime.
I think that's a really interesting characteristic. It's made me less excited about boil-the-ocean attempts at defining a single standard and getting everyone to support it at once.
[ This thread may not be the best place to raise this idea, since the Python Data API Standards project isn't really in the same realm as the web API formats I'm talking about here ]
I agree that interfaces like Datasette are a fantastic idea. But, it's not the same thing. Think of this more like the SQL standard. What would you do if SQL did not exist and there were no common ways to discuss querying databases?
I don’t think your ideas are random nor out of place. Durable data accessible by different clients is an important property that bleeds into the data science realm. Apache Arrow seems to partially tackle this problem by moving the data to shared memory that can be accessed by different runtimes like Python and R.
There are a couple of problems I see with SQLite used as a common data format:
1. SQLite is a state machine that only stores the most recent version of mutable (binary) tables so change control is non-trivial.
2. Matrices/Tensors are not naturally stored in relational tables.
{kind=link}